Cassandra Architecture
Cassandra was designed to address many architecture requirements. The most important requirement is to ensure there is no single point of failure. This means that if there are 100 nodes in a cluster and a node fails, the cluster should continue to operate.
This is in contrast to Hadoop where the namenode failure can cripple the entire system. Another requirement is to have massive scalability so that a cluster can hold hundreds or thousands of nodes. It should be possible to add a new node to the cluster without stopping the cluster.
Further, the architecture should be highly distributed so that both processing and data can be distributed. Also, high performance of read and write of data is expected so that the system can be used in real-time.




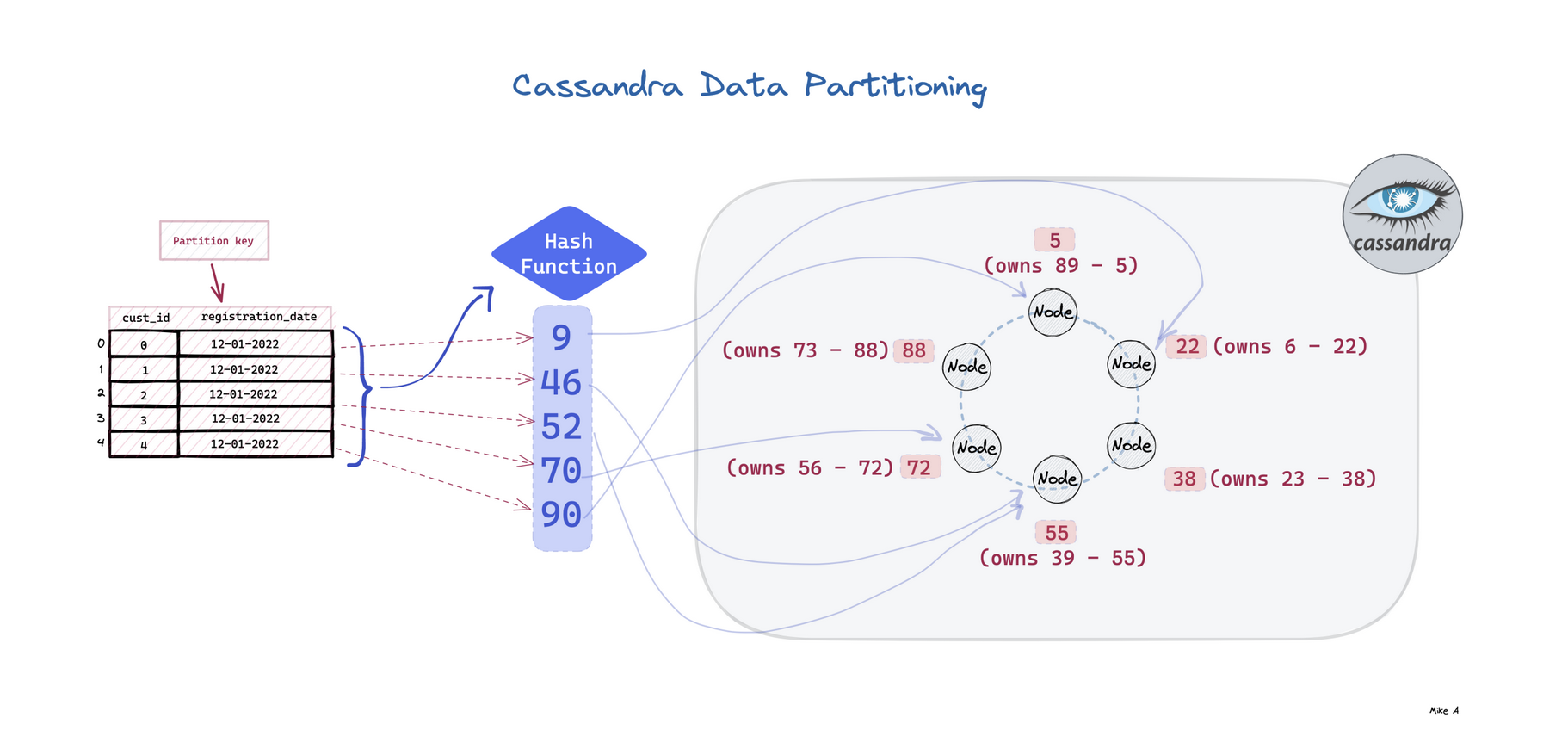
Architecture Components:
- Nodes and Clusters: A node is a single machine running Cassandra, and a cluster is a collection of those nodes.
- Data Center: A collection of related nodes, typically grouped by physical proximity or usage.
- Partitioner: Determines how data is distributed across the nodes in the cluster.
- Replication Strategy: Defines how many copies of data exist and where they are stored.
- Node: A Cassandra node is a place where data is stored.
- Data center: Data center is a collection of related nodes.
- Cluster: A cluster is a component which contains one or more data centers.
- Commit log: In Cassandra, the commit log is a crash-recovery mechanism. Every write operation is written to the commit log.
- Mem-table: A mem-table is a memory-resident data structure. After commit log, the data will be written to the mem-table. Sometimes, for a single-column family, there will be multiple mem-tables.
- SSTable: It is a disk file to which the data is flushed from the mem-table when its contents reach a threshold value.
- Bloom filter: These are nothing but quick, nondeterministic, algorithms for testing whether an element is a member of a set. It is a special kind of cache. Bloom filters are accessed after every query.
Key Features of Apache Cassandra
Some of the features of Cassandra architecture are as follows:
- Cassandra is designed such that it has no master or slave nodes.
- It has a ring-type architecture, that is, its nodes are logically distributed like a ring.
- Data is automatically distributed across all the nodes.
- Similar to HDFS, data is replicated across the nodes for redundancy.
- Data is kept in memory and lazily written to the disk.
- Hash values of the keys are used to distribute the data among nodes in the cluste
https://docs.nomagic.com/display/TWCloud190SP1/Installing+and+configuring+Cassandra+on+Linux
https://youkudbhelper.wordpress.com/2020/01/29/steps-to-install-cassandra-on-linux/
https://youkudbhelper.wordpress.com/2020/05/17/how-to-add-new-vnode-to-the-existing-datacenter-in-cassandra-cluster/
https://youkudbhelper.wordpress.com/2020/05/17/steps-to-add-a-new-datacenter-to-a-cluster-in-cassandra/
https://youkudbhelper.wordpress.com/2020/05/17/steps-to-decommission-a-datacenter-in-cassandra/
https://youkudbhelper.wordpress.com/2021/09/01/list-of-handful-cassandra-commands-to-improve-productivity/
https://youkudbhelper.wordpress.com/2021/10/05/important-cassandra-questions-that-you-must-know/

No comments:
Post a Comment