awk 'pattern {action}' filename
Reads one line at a time from file, checks for pattern match, performs action if pattern matched pattern.
NR is a special awk variable meaning the line number of the current record
can use a line number, to select a specific line, by comparing it to NR (for example: NR == 2)
can specify a range of line numbers (for example: NR == 2, NR == 4)
can specify a regular expression, to select all lines that match
$n are special awk variables, meaning the value of the nth field (field delimiter is space or tab)
$0 is the entire record
can use field values, by comparing to $n (for example: $3 == 65)
every line is selected if no pattern is specified
Instructions
print - print line(s) that match the pattern, or print fields within matching lines
print is default if no action is specified
there are many, many instruction, including just about all C statements with similar syntax
other instructions will be covered in future courses
examples, using the file testfile.
awk 'NR == 2, NR == 4' testfile - print the 2nd through 4th lines (default action is to print entire line)
awk '/chevy/' testfile - print only lines matching regular expression, same as grep 'chevy' testfile
awk '{print $3, $1}' testfile - print third and first field of all lines (default pattern matches all lines)
awk '/chevy/ {print $3, $1}' testfile - print third and first fiield of lines matching regular expression
awk '$3 == 65' testfile - print only lines with a third field value of 65
awk '$5 < = 3000' testfile - print only lines with a fifth field value that is less than or equal to 3000
awk '{print $1}' testfile - print first field of every record
awk '{print $3 $1}' testfile
awk '{print $3, $1}' testfile - inserts output field separator (variable OFS, default is space)
awk -F, '{print $2}' testfile - specifies that , is input field separator, default is space or tab
awk '$2 ~ /[0-9]/ {print $3, $1}' testfile - searches for reg-exp (a digit) only in the second field
awk '{printf "%-30s%20s\n", $3, $2}' testfile - print 3rd field left-justified in a 30 character field, 2nd field right-justified in a 20 character field, then skip to a new line (required with printf)
awk '$3 <= 23' testfile - prints lines where 3rd field has a value <= 23
awk '$3 <='$var1' {print $3}' testfile - $var1 is a shell variable, not an awk variable, e.g. first execute: var1=23
awk '$3<='$2' {$3++} {print $0}' testfile - if field 3 <= argument 2 then increment field 3, e.g. first execute: set xxx 23
awk '$3> 1 && $3 < 23' testfile - prints lines where 3rd field is in range 1 to 23
awk '$3 < 2 || $3 > 4' testfile - prints lines where 3rd field is outside of range 2 to 4
awk '$3 < "4"' testfile - double quotes force string comparison
NF is an awk variable meaning # of fields in current record
awk '! (NF == 4)' testfile - lines without 4 fields
NR is an awk variable meaning # of current record
awk 'NR == 2,NR==7' testfile - range of records from record number 2 to 7
BEGIN is an awk pattern meaning "before first record processed"
awk 'BEGIN {OFS="~"} {print $1, $2}' testfile - print 1st and 2nd field of each record, separated by ~
END is an awk pattern meaning "after last record processed"
awk '{var+=$3} END {print var}' testfile - sum of 3rd fields in all records
awk '{var+=$3} END {print var/NR}' testfile - average of 3rd fields in all records - note that awk handles decimal arithmetic
awk '$5 > var {var=$5} END {print var}' testfile - maximum of 5th fields in all records
awk '$5 > var {var=$5} END {print var}' testfile - maximum of 5th fields in all records
sort -rk5 testfile | awk 'NR==1 {var=$5} var==$5 {print $0}' - print all records with maximum 5th field
Simple awk operations involving functions within the command line:
awk '/chevy/' testfile
# Match lines (records) that contain the keyword chevy note that chevy is a regular expression...
awk '{print $3, $1}' testfile
# Pattern not specified - therefore, all lines (records) for fields 3 and 1 are displayed
# Note that comma (,) between fields represents delimiter (ie. space)
awk '/chevy/ {print $3, $1}' testfile
# Similar to above, but for chevy
awk '/^h/' testfile
# Match testfile that begin with h
awk '$1 ~ /^h/' testfile ### useful ###
# Match with field #1 that begins with h
awk '$1 ~ /h/' testfile
# Match with field #1 any epression containing the letter h
awk '$2 ~ /^[tm]/ {print $3, $2, "$" $5}' testfile
# Match testfile that begin with t or m and display field 3 (year), field 2 (model name) and then $ followed by field 4 (price)
--------------------------------------------------------------------------------------------------
Complex awk operations involving functions within the command line:
awk ?/chevy/ {print $3, $1}? testfile
# prints 3rd & 1st fields of record containing chevy
awk ?$1 ~ /^c/ {print $2, $3}? testfile
# print 2nd & 3rd fields of record with 1st field beginning with c
awk ?NR==2 {print $1, $4}? testfile
# prints 1st & 4th fields of record for record #2
awk ?NR==2, NR==8 {print $2, $3}? testfile
# prints 2nd & 3rd fields of record for records 2 through 8
awk ?$3 >= 65 {print $3, $1}? testfile
# prints 3rd & 1st fields of record with 3rd field >= 65
awk ?$5 >= ?2000? && $5 < ?9000? {print $2, $3}? testfile
# prints 2nd & 3rd fields of record within range of 2000 to under 9000
Thursday, July 30, 2009
Tuesday, July 28, 2009
MySQL Replication : Purged binary logs
Yesterday I have found that there is no space left on server of MySQL master and on Slave. Once I debugged I have come to know that there is GB's of bin-log files on Master and relay-log on Slave.
Its due to I have forget to add a expire_logs_days Variable in my.cnf during the configuration of replication server.
# expire_logs_days = 7
It will purged binary logs older than 7 days.The old logs will be purged during the next bin-log switch.
Or, You can also delete bin-log manually using command :
PURGE BINARY LOGS TO 'mysql-bin.010';
PURGE BINARY LOGS BEFORE '2008-04-02 22:46:26';
Its due to I have forget to add a expire_logs_days Variable in my.cnf during the configuration of replication server.
# expire_logs_days = 7
It will purged binary logs older than 7 days.The old logs will be purged during the next bin-log switch.
Or, You can also delete bin-log manually using command :
PURGE BINARY LOGS TO 'mysql-bin.010';
PURGE BINARY LOGS BEFORE '2008-04-02 22:46:26';
Thursday, July 02, 2009
MYSQL: slow queries log
MySQL has built-in functionality that allows you to log SQL queries to a file , You can enable the full SQL queries logs to a file or only slow running queries log. It is easy for us to troubleshoot/ debug the sql statement if SQL queries log enable , The slow query log is used to find queries that take a long time to execute and are therefore candidates for optimization.
To enable you just need to add some lines to your my.cnf file, and restart. Add the following:
* To enable slow Query Log only
log-slow-queries = /var/log/mysql/mysql-slow.log
long_query_time = 1
After enabling slow query, mysqld writes a statement to the slow query log file and it consists of all SQL statements that took more than long_query_time seconds to execute. The time to acquire the initial table locks is not counted as execution time. mysqld only log after SQL statements has been executed and after all locks have been released, so log order might be different from execution order. The minimum and default values of long_query_time are 1 and 10, respectively.
* To enable full Log Query
log=/var/log/mysqldquery.log
The above will log all queries to the log file.
Selecting Queries to Optmize
• The slow query log
– Logs all queries that take longer than long_query_time
– Can also log all querie s that don’t use indexes with
--log-queries-not-using-indexes
– To log slow administatve commands use
--log-slow-admin-statements
– To analyze the contents of the slow log use
mysqldumpslow
To enable you just need to add some lines to your my.cnf file, and restart. Add the following:
* To enable slow Query Log only
log-slow-queries = /var/log/mysql/mysql-slow.log
long_query_time = 1
After enabling slow query, mysqld writes a statement to the slow query log file and it consists of all SQL statements that took more than long_query_time seconds to execute. The time to acquire the initial table locks is not counted as execution time. mysqld only log after SQL statements has been executed and after all locks have been released, so log order might be different from execution order. The minimum and default values of long_query_time are 1 and 10, respectively.
* To enable full Log Query
log=/var/log/mysqldquery.log
The above will log all queries to the log file.
Selecting Queries to Optmize
• The slow query log
– Logs all queries that take longer than long_query_time
– Can also log all querie s that don’t use indexes with
--log-queries-not-using-indexes
– To log slow administatve commands use
--log-slow-admin-statements
– To analyze the contents of the slow log use
mysqldumpslow
Subscribe to:
Comments (Atom)
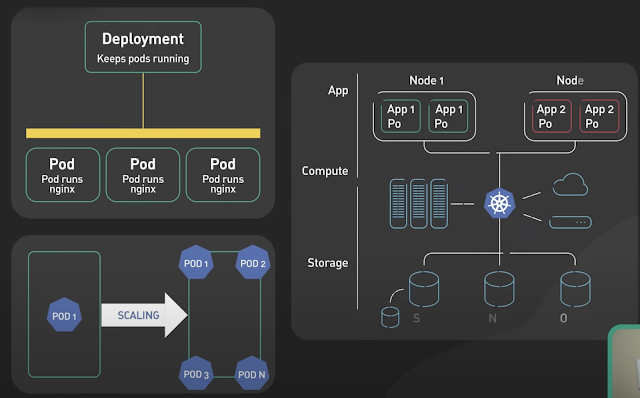
Basics of Kubernetes
Kubernetes, often abbreviated as K8s , is an open-source platform designed to automate the deployment, scaling, and management of container...
-
The Unix top command is designed to help users determine which processes are running and which applications are using more memory or process...
-
 IOPS (input/output operations per second) is the standard unit of measurement for the maximum number of reads and writes to non-contiguous ...
IOPS (input/output operations per second) is the standard unit of measurement for the maximum number of reads and writes to non-contiguous ... -
 MySQL's InnoDB storage engine data refresh every situation. This post from InnoDB down, look at the data from the memory to the InnoDB ...
MySQL's InnoDB storage engine data refresh every situation. This post from InnoDB down, look at the data from the memory to the InnoDB ...