MySQL's InnoDB storage engine data refresh every situation. This post from InnoDB down, look at the data from the memory to the InnoDB actually written on the media storage device in the end there is a buffer in which to work.
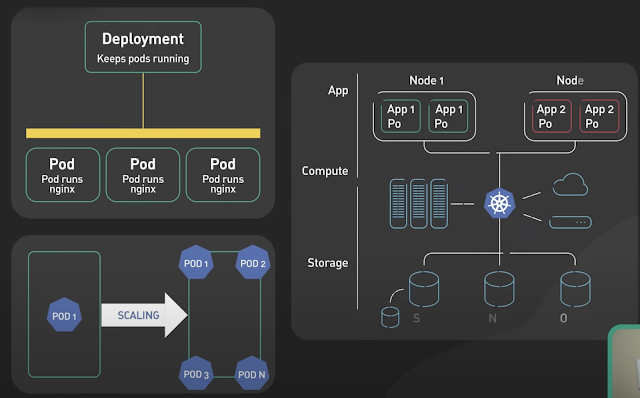
We look through the following figure at the relevant buffer:
From the figure above, we can see that the InnoDB data to disk need to go through
- InnoDB buffer pool, Redo log buffer. This is a buffer InnoDB application itself.
- page cache / Buffer cache (can be bypassed by o_direct). This is a buffer vfs layer.
- Inode cache / directory buffer. This is the buffer vfs layer. Need to refresh by O_SYNC or fsync ().
- Write-Back buffer. (You can set parameters to bypass the memory controller)
- Disk on-borad buffer. (Can be bypassed by setting the disk controller parameters)
Here we use the term "buffer" (typically buffer) to represent the data write scratch, using the term "cache" (usually cache) to represent the data read scratch. As the name suggests, due to the difference between the rate of the underlying storage device and memory buffer is used to temporarily "slow" to the underlying storage device IO's "red" attack. Cache is mainly in memory temporarily "stored" data read from the disk, for subsequent access to these data without accessing the slow underlying storage device again.
InnoDB layerThe layers are placed in host memory buffer, it is intended primarily at the application layer to manage their own data, read and write operations to avoid slow response times affect the InnoDB.
InnoDB layer consists of two buffer:
redo log buffer and
innodb buffer pool. redo log buffer for temporarily storing the redo log redo log log write, InnoDB buffer pool from disk storage device to read the InnoDB data, also for InnoDB data write buffer, namely the dirty pages of data. If the host is powered off or abnormal downtime MySQL, innodb buffer pool will not be promptly flushed to disk, so you can only use InnoDB redo log to roll forward from a checkpoint; and if you can not redo log buffer is flushed to disk, then since redo log in loss of data, even if the use of redo roll before the transaction submitted by users because there is no real record of the non-volatile disk medium, it lost out.
Control redo log buffer refresh timing parameters are
innodb_flush_log_at_trx_commit, and control redo log buffer and parameters innodb buffer pool refresh mode is
innodb_flush_method. Aiming at these two parameters are very much in detail, we are here mainly from the perspective of the buffer to resolve.
Innodb_flush_log_at_trx_commit :
Control redo log buffer of innodb_flush_log_at_trx_commit currently supports three different parameter values 0,1,2
In addition, the update about changes innodb_flush_log_at_trx_commit = 5.6 2:00:
<5 .6.6:="" buffer="" data="" disk="" every="" flush="" flushed="" in="" innodb_flush_log_at_timeout="" is="" log="" nbsp="" p="" redo="" second="" seconds.="" the="" to="">
Innodb_flush_method :
Control innodb buffer pool of innodb_flush_method currently supports four different parameter values:
- fdatasync
- O_DSYNC
- O_DIRECT
- O_DIRECT_NO_FSYNC
Here we note that there are several issues:
- innodb_flush_method specify not only the "Data File" refresh mode, also specify the "log file" refresh mode.
- These parameters there are no parameters in the configuration windows environment, and now we are beginning not bird Gates brother it? In fact, wrote in a note inside, windows on the use async_unbuffered, and can not be modified, so the list is not written inside.
- The first three parameters only allows 6.6 and 5.6.6 used in previous versions, starting from the 5.6.7 adds O_DIRECT_NO_FSYNC. That opens the file with the O_DIRECT, but no fsync () to synchronize data. Because of this relatively new Linux kernel and part of the file system, use O_DIRECT can ensure data security, without special then fsync () to synchronize, ensure meta data is flushed to non-volatile disk media. For example: XFS not use this parameter. O_DIRECT bypassing the page cache, why use fsync () and then refresh the following, we devoted the next section.
- Some would say there is a small document referense bug, 6.6 versions prior to default is fdatasync, but there is not even within fdatasync value Valid Values can be specified.

In fact, here is his deliberate, because fdatasync () and fsync () is not the same as the difference between O_DSYNC and O_SYNC same. Fdatasync and O_DSYNC only for data synchronization, fsync () and O_SYNC for data and metadata meta-data synchronization. But MySQL fdatasync parameter values used to indicate "data file" and "Log File" is fsync () to open (note: not fdatasync ()), this is a historical reason, so 5.6 deliberately remove it from the optional values, to avoid misunderstanding. Of course, if you still want to use fsync () to sync, then do not specify anything for innodb_flush_method it.
- Apart O_DIRECT_NO_FSYNC, InnoDB uses fsync () to refresh "the data file." Exception is O_DIRECT_NO_FSYNC here.
-
If O_DIRECT, O_DIRECT_NO_FSYNC, data files are opened O_DIRECT (on
solaris () opened with directio, if Innodb data files are placed in a
separate device, you can use forcedirectio makes the whole file system
with directio when the mount is open Here specified as innodb instead
because MySQL, MyISAM do not use directio ()
Virtual File System (VFS) Layer
The buffer layer are placed in host memory, its main purpose is to buffer data in the operating system layer, to avoid slow block device reads and writes affect the response time of the IO.
Careful study O_DIRECT / O_SYNC tag
Involved in the discussions preceding redo log buffer and innodb buffer pool in a lot of data refresh and data security issues, we in this section, devoted to the meaning O_DIRECT / O_SYNC tags.

The figure, we see that the layer mainly page_cache / buffer cache / Inode-cache / Directory cache. Which page_cache / buffer cache main memory for buffering data and block data structure. The inode-cache for buffering inode, directory-cache directory structure for buffering data.
Depending on the file systems and operating systems, in general, a file write operation consists of two parts, the writing operation of the data itself, and the file attributes (metadata metadata) writes (here the file attributes include directory, inode, etc).
Understand these later, we can say relatively simple clear sign of the meaning of each:

- Difference
O_DSYNC and fdatasync () is: is all refreshed for the corresponding
page cache and buffer cache at the time of each IO submitted; or write
to certain data after calling fdatasync () the moment of the whole page
cache and buffer cache refresh. O_SYNC and fsync () of the difference between empathy.
- The main difference between the page cache and buffer cache is that one is for the actual file data, a block-oriented devices.
Using the open () mode in the upper VFS open those files using mkfs to
make the file system, you will use the page cache and buffer cache, and
if you use the dd this way on the Linux operating system to operate a
Linux block device, You can only use buffer cache.
-
O_DSYNC and O_SYNC difference lies: O_DSYNC tell the kernel, when data
is written to the file only when data is written to the disk, the write
operation is completed (write before returning success).
O_SYNC O_DSYNC more stringent than, not only requires the data has been
written to disk, and attribute the corresponding data files (such as
file inode, changes in relevant directories, etc.) need to be updated to
complete the write operation to be successful. O_SYNC seen to do more than O_DSYNC operation.
-
Open () the referense There is also a O_ASYNC, it is mainly used for
terminals, pseudoterminals, sockets, and pipes / FIFOs, the signal
driving the IO, sends a signal (SIGIO) When the device can read and
write, the application process to capture this signal for IO operations.
- O_SYNC and O_DIRECT are synchronized to write, that success will only write return.
Looking back, we will look at innodb_flush_log_at_trx_commit configuration is better understood. Why O_DIRECT IO directly bypassing the page cache / buffer cache ever need to fsync (), it is to put inode cache directory cache and metadata are flushed to the storage device.
And because updating the kernel and file system, the file system can guarantee some assurance in O_DIRECT mode without fsync () to synchronize the metadata will not cause data security issues, so InnoDB also provided O_DIRECT_NO_FSYNC way.
Of course, O_DIRECT to read and write are effective, especially for reading, it can ensure that read data is read from the storage device, rather than the cache. Avoid data cache data and storage devices is inconsistent (ie you by DRBD block device will update the underlying data, and for the non-distributed file system cache contents and storage devices on inconsistent data) . But we are here focused on the buffer (write buffer), it is not discussed in depth. This problem.
O_DIRECT advantages and disadvantages
Most
of the recommended innodb_flush_method parameter values are
recommended to use in O_DIRECT, even in percona server branch also
provides ALL_O_DIRECT, also used for the log file is opened O_DIRECT.
Advantages:
-
Saving operating system memory: O_DIRECT bypass the page cache / buffer
cache, thus avoiding InnoDB read and write data in operating system
takes up less memory, the more memory to leave a innodb buffer pool to
use.
- Saving CPU. In addition, the memory storage device to transfer mode mainly poll, interrupt and DMA mode. Use O_DIRECT way to make use of the operating system prompt DMA mode for storage devices operate, saving CPU.
Weaknesses
- Byte alignment.
O_DIRECT way required to write data, the memory is byte-aligned
(aligned manner depending on the kernel and file system being used). This requires data at the time of writing need additional alignment operation. Via / sys / block / sda / queue / logical_block_size know aligned size, usually 512 bytes.
- IO can not be merged.
O_DIRECT bypassing the page cache / buffer cache to write directly to
the storage device, so that if the same piece of data can not be hit
repeatedly written in memory, page cache / buffer cache to write the
function can not be merged into effect.
- Lower sequential read and write efficiency.
If you use O_DIRECT to open a file, the read / write operations will
skip the cache, the read / write directly on the storage device.
Because there is no cache, so the sequential read and write file usage
efficiency O_DIRECT this small IO requests is relatively low.
In general, use O_DIRECT to set innodb_flush_method not 100% of all applications and scenarios are applicable.
Storage Controller Layer
The
layers are placed in the corresponding buffer memory controller
on-board cache, and its main purpose is to buffer data in memory
controller layer to avoid slow block device reads and writes affect the
response time of the IO. When data is fsync () and other brush to the storage layer, it is first sent to the storage controller layer. Common storage controller is Raid card, and now most of the Raid card has 1G or greater storage capacity.
This buffer is generally volatile memory, through the onboard battery /
capacitor to ensure that the data "volatile memory" of power after the
machine will still be synchronized to the underlying disk storage media.
About storage controller we have some aspects to note:
- write back / write through:
With respect to whether the buffer, the general storage controllers provide write back and write through two ways.
Under write back mode, the operating system writes data requests
submitted written directly to buffer it returns success; in write
through mode, the operating system writes data submitted written request
must be true underlying disk media before returning success.
- Battery / capacitor differences:
In order to guarantee that power down the machine data in the
"volatile" buffer can be instantly updated to the underlying disk media,
there is a battery / capacitor to ensure the storage controller.
Common battery capacity fade problem, that is to say from time to time,
the on-board battery charge and discharge must be controlled to ensure
that the battery capacity.
In the battery charging and discharging process, is set to write-back
memory controller will automatically become write through. The charge-discharge cycles (Learn Cycle cycle) is generally 90 days, LSI card can MegaCli to see:
#MegaCli -AdpBbuCmd -GetBbuProperties-AAll
BBU Properties for Adapter: 0
Auto Learn Period: 90 Days
Next Learn time: Tue Oct 14 05:38:43 2014
Learn Delay Interval: 0 Hours
Auto-Learn Mode: Enabled
If you find every once in IO request response time suddenly slow down, there may be a problem, oh.
By MegaCli -AdpEventLog -GetEvents -f mr_AdpEventLog.txt -aALL log in
Event Description: Battery started charging can determine whether there
has occurred a case of charging and discharging.
Since the battery have this problem, a new Raid card is configured
capacitance to ensure data "volatile" buffer can be instantly updated to
the underlying disk media, so there is no question of charging and
discharging.
- read / write ratio:
HP's smart array provides read and write cache distinction (Accelerator Ratio),
hpacucli ctrl all show config detail | grep 'Accelerator Ratio'
Accelerator Ratio: 25% Read / 75% Write
So you can set the ratio of cache read and write buffer cache for applications based on the actual situation.
- Open Direct IO
In order to allow the top of the device using Direct IO way to bypass
the raid card, you need to set to open DirectIO Raid mode:
/ Opt / MegaRAID / MegaCli / MegaCli64 -LDSetProp -Direct -Immediate -Lall -aAll
- LSI flash raid:
We mentioned above the "volatile" buffer, if we now have a non-volatile
buffer, and the capacity of several hundred G, such as the memory
controller buffer to the underlying device is not more speed?
As a veteran of the Raid card vendors, LSI now there is such a memory
controller, use the write back mode and more dependent on the memory
controller buffer applications can consider using this type of storage
controller.
- write barriers
Currently raid card cache if a battery or capacitor protection for
Linux is not visible, so the Linux system log files in order to ensure
consistency, the default will open write barriers, that is, it will
continue to refresh the "volatile "buffer, it will greatly reduce IO
performance.
So if you are convinced that the underlying cells can guarantee
"volatile" buffer will brush to the underlying disk devices, you can add
the disk mount -o nobarrier time.
Disk controller layer
The buffer layer are placed in the corresponding on-board disk controller cache. Storage device firmware (firmware) will be sorted by the rules will be synchronized to the media writes really go.
This is mainly to ensure sequential write, mechanical disks, so you can
try to make the move a head to do more disk write operations.
In general, DMA controller on the disk of this layer is carried out
through DMA direct memory access controller, capable of saving CPU
resources.
For the mechanical hard drive, because on conventional disk device and
no battery capacitors, we can not guarantee that all data on the disk
cache inside the machine power failure timely synchronized to the media,
so we strongly recommend that closed off the disk cache.
Disk cache memory controller can turn off the layer. For example, using MegaCli off command is as follows:
MegaCli -LDSetProp -DisDskCache -Lall -aALL
Summary
From InnoDB to the final medium, we have gone through all kinds of
cushion, their purpose is very clear, it is to solve: speed memory and
disk does not match the problem, or that the disk speed is too slow.
Additionally, in fact, most know whether the data should buffer / cache
or the application itself, VFS, storage controllers and disks can only
be written by the delay (in order to merge duplicate IO, making random
writes into sequential writes) to alleviate the underlying storage
device slow slow response speed caused problems.
Therefore, the type of database application will be to manage the
buffer, and then try to avoid buffer operating system and the underlying
equipment.
But in fact occur due to the current difference in speed SSDs and PCIe
Flash SSD cards, memory, and disk is greatly reduced between these
buffers if necessary, what can be improved hardware and software,
hardware and software engineers, a major challenge.












{kind=link}