Secure Deletion of Data from Magnetic and Solid-State Memory
`shred': Remove files more securely
`shred' overwrites devices or files, to help prevent even very
expensive hardware from recovering the data.
Ordinarily when you remove a file (*note rm invocation::), the data
is not actually destroyed. Only the index listing where the file is
stored is destroyed, and the storage is made available for reuse.
There are undelete utilities that will attempt to reconstruct the index
and can bring the file back if the parts were not reused.
On a busy system with a nearly-full drive, space can get reused in a
few seconds. But there is no way to know for sure. If you have
sensitive data, you may want to be sure that recovery is not possible
by actually overwriting the file with non-sensitive data.
The best way to remove something irretrievably is to destroy the
media it's on with acid, melt it down, or the like. For cheap
removable media like floppy disks, this is the preferred method.
However, hard drives are expensive and hard to melt, so the `shred'
utility tries to achieve a similar effect non-destructively.
`Secure Deletion of Data from Magnetic and Solid-State Memory', from the
proceedings of the Sixth USENIX Security Symposium (San Jose,
California, 22-25 July, 1996).
visit: http://www.cs.auckland.ac.nz/~pgut001/pubs/secure_del.html
So. `shred' a linux command : Remove files more securely
shred [OPTION]... FILE[...]
look man page how to use..
Tuesday, September 26, 2006
Monday, September 25, 2006
Danger of 'Ctrl+C' on the Web
We do copy various data by ctrl+c for pasting elsewhere. This copied data is stored in clipboard and is accessible from the net by a combination of Javascripts and ASP.
Just try this:
1) Copy any text by 'ctrl+c'
2) Click the Link: www.sourcecodesworld.com/special/clipboard.asp
You will see the text you copied on the Screen which was accessed by this web page. (Check it out !!)
Do not keep sensitive data (like passwords, reditcard numbers, PIN etc.) in the clipboard while surfing the web. It is extremely easy to extract the text stored in the clipboard to steal your sensitive information.
Be cautious ...
To avoid Clipboard Hack Problem, do the following:
1) In Internet Explorer, Go to Tools -> Internet options -> Security
2) Press Custom level.
3) In the security settings, select disable under Allow paste operations via script and click on 'OK. (Now the contents of your clipboard are safe.)
It doesn't work on firefox.
Happy Surfing......
Just try this:
1) Copy any text by 'ctrl+c'
2) Click the Link: www.sourcecodesworld.com/special/clipboard.asp
You will see the text you copied on the Screen which was accessed by this web page. (Check it out !!)
Do not keep sensitive data (like passwords, reditcard numbers, PIN etc.) in the clipboard while surfing the web. It is extremely easy to extract the text stored in the clipboard to steal your sensitive information.
Be cautious ...
To avoid Clipboard Hack Problem, do the following:
1) In Internet Explorer, Go to Tools -> Internet options -> Security
2) Press Custom level.
3) In the security settings, select disable under Allow paste operations via script and click on 'OK. (Now the contents of your clipboard are safe.)
It doesn't work on firefox.
Happy Surfing......
Friday, September 22, 2006
Recover from rm
In order to undelete a file, you must know the following things:
• On which device your file was stored
• What kind of file system was used (eg. ext2, reiserFS, vfat)
To find it out, type 'mount | column -t'
Or
echo "DEVICE DIRECTORY FS-TYPE" > tmp; mount | cut -d" " -f1,3,5 | sort >> tmp; cat tmp | column -t | sed -e "1s/.*/`tput smso`&`tput rmso`/"
The output should be something like this:
bash$ mount | column -t
/dev/hda5 on / type ext2 (rw)
proc on /proc type proc (rw)
usbdevfs on /proc/bus/usb type usbdevfs (rw)
devpts on /dev/pts type devpts (rw)
/dev/hda1 on /mnt/windows/C type vfat (rw,noexec,nosuid,nodev)
/dev/hda6 on /mnt/windows/E type vfat (rw,noexec,nosuid,nodev)
/dev/hdc5 on /mnt/oldwin type vfat (rw,noexec,nosuid,nodev)
Now, of which (printed) directory was the directory of your deleted file a subdirectory? E.g. if your file was stored on /home/user , you'll have to look for '/', since no closer match can be found. Found it? Cool, right now it's a piece of cake to find the device on which the file was stored and the filesystem type of the device.
If you really need to undelete a file, that's the way to do it:
grep -a -B[size before] -A[size after] 'text' /dev/[your_partition]
Replace [size before], [size after] and [your_partition] with something meaningfull. Don't know what your partition is? Read the Linux undelete
.g.: If you want to undelete a letter (+- 200 lines) starting with "Hi mum" which was stored on /dev/hda1 you can try:
grep -a -B2 -A200 "Hi mum" /dev/hda1
Make sure you do this as root (System administrator)
• On which device your file was stored
• What kind of file system was used (eg. ext2, reiserFS, vfat)
To find it out, type 'mount | column -t'
Or
echo "DEVICE DIRECTORY FS-TYPE" > tmp; mount | cut -d" " -f1,3,5 | sort >> tmp; cat tmp | column -t | sed -e "1s/.*/`tput smso`&`tput rmso`/"
The output should be something like this:
bash$ mount | column -t
/dev/hda5 on / type ext2 (rw)
proc on /proc type proc (rw)
usbdevfs on /proc/bus/usb type usbdevfs (rw)
devpts on /dev/pts type devpts (rw)
/dev/hda1 on /mnt/windows/C type vfat (rw,noexec,nosuid,nodev)
/dev/hda6 on /mnt/windows/E type vfat (rw,noexec,nosuid,nodev)
/dev/hdc5 on /mnt/oldwin type vfat (rw,noexec,nosuid,nodev)
Now, of which (printed) directory was the directory of your deleted file a subdirectory? E.g. if your file was stored on /home/user , you'll have to look for '/', since no closer match can be found. Found it? Cool, right now it's a piece of cake to find the device on which the file was stored and the filesystem type of the device.
If you really need to undelete a file, that's the way to do it:
grep -a -B[size before] -A[size after] 'text' /dev/[your_partition]
Replace [size before], [size after] and [your_partition] with something meaningfull. Don't know what your partition is? Read the Linux undelete
.g.: If you want to undelete a letter (+- 200 lines) starting with "Hi mum" which was stored on /dev/hda1 you can try:
grep -a -B2 -A200 "Hi mum" /dev/hda1
Make sure you do this as root (System administrator)
Proxy server types and uses for HTTP Server
Proxy server
In an enterprise that uses the Internet, a proxy server is a server that acts as an intermediary between a workstation user and the Internet so that the enterprise can ensure security, administrative control, and caching service. A proxy server is associated with or part of a gateway server that separates the enterprise network from the outside network and a firewall server that protects the enterprise network from outside intrusion.
Proxy servers receive requests intended for other servers and then act to fulfill, forward, redirect, or reject the requests. Exactly which service is carried out for a particular request is based on a number of factors which include: the proxy server's capabilities, what is requested, information contained in the request, where the request came from, the intended destination, and in some cases, who sent the request.
An advantage of a proxy server is that its cache can serve all users. If one or more Internet sites are frequently requested, these are likely to be in the proxy's cache, which will improve user response time. In fact, there are special servers called cache servers. A proxy can also do logging.
HTTP Server (powered by Apache) has proxy server capabilities built in. Activating these services is simply a matter of configuration. This topic explains three common proxy concepts: forward proxy, reverse proxy, and proxy chaining.
Forward proxy :
A forward proxy is the most common form of a proxy server and is generally used to pass requests from an isolated, private network to the Internet through a firewall. Using a forward proxy, requests from an isolated network, or intranet, can be rejected or allowed to pass through a firewall. Requests may also be fulfilled by serving from cache rather than passing through the Internet. This allows a level of network security and lessens network traffic.
A forward proxy server will first check to make sure a request is valid. If a request is not valid, or not allowed (blocked by the proxy), it will reject the request resulting in the client receiving an error or a redirect. If a request is valid, a forward proxy may check if the requested information is cached. If it is, the forward proxy serves the cached information. If it is not, the request is sent through a firewall to an actual content server which serves the information to the forward proxy. The proxy, in turn, relays this information to the client and may also cache it, for future requests.
Reverse proxy
A reverse proxy is another common form of a proxy server and is generally used to pass requests from the Internet, through a firewall to isolated, private networks. It is used to prevent Internet clients from having direct, unmonitored access to sensitive data residing on content servers on an isolated network, or intranet. If caching is enabled, a reverse proxy can also lessen network traffic by serving cached information rather than passing all requests to actual content servers. Reverse proxy servers may also balance workload by spreading requests across a number of content servers. One advantage of using a reverse proxy is that Internet clients do not know their requests are being sent to and handled by a reverse proxy server. This allows a reverse proxy to redirect or reject requests without making Internet clients aware of the actual content server (or servers) on a protected network.
A reverse proxy server will first check to make sure a request is valid. If a request is not valid, or not allowed (blocked by the proxy), it will not continue to process the request resulting in the client receiving an error or a redirect. If a request is valid, a reverse proxy may check if the requested information is cached. If it is, the reverse proxy serves the cached information. If it is not, the reverse proxy will request the information from the content server and serve it to the requesting client. It also caches the information for future requests.
Proxy chaining
A proxy chain uses two or more proxy servers to assist in server and protocol performance and network security. Proxy chaining is not a type of proxy, but a use of reverse and forward proxy servers across multiple networks. In addition to the benefits to security and performance, proxy chaining allows requests from different protocols to be fulfilled in cases where, without chaining, such requests would not be possible or permitted. For example, a request using HTTP is sent to a server that can only handle FTP requests. In order for the request to be processed, it must pass through a server that can handle both protocols. This can be accomplished by making use of proxy chaining which allows the request to be passed from a server that is not able to fulfill such a request (perhaps due to security or networking issues, or its own limited capabilities) to a server that can fulfill such a request.
The first proxy server in a chain will check to make sure a request is valid. If a request is not valid, or not allowed (blocked by the proxy), it will reject the request resulting in the client receiving an error or a redirect. If a request is valid, the proxy may check if the requested information is cached and simply serve it from there. If the requested information is not in cache, the proxy will pass the request on to the next proxy server in the chain. This server also has the ability to fulfill, forward, redirect, or reject the request. If it acts to forward the request then it too passes the request on to yet another proxy server. This process is repeated until the request reaches the last proxy server in the chain. The last server in the chain is required to handle the request by contacting the content server, using whatever protocol is required, to obtain the information. The information is then relayed back through the chain until it reaches the requesting client.
The Squid web caching proxy server
Users configure their web browsers to use the Squid proxy server instead of going to the web directly. The Squid server then checks its web cache for the web information requested by the user. It will return any matching information that finds in its cache, and if not, it will go to the web to find it on behalf of the user. Once it finds the information, it will populate its cache with it and also forward it to the user's web browser.
As you can see, this reduces the amount of data accessed from the web. Another advantage is that you can configure your firewall to only accept HTTP web traffic from the Squid server and no one else. Squid can then be configured to request usernames and passwords for each user that users its services. This provides simple access control to the Internet
In an enterprise that uses the Internet, a proxy server is a server that acts as an intermediary between a workstation user and the Internet so that the enterprise can ensure security, administrative control, and caching service. A proxy server is associated with or part of a gateway server that separates the enterprise network from the outside network and a firewall server that protects the enterprise network from outside intrusion.
Proxy servers receive requests intended for other servers and then act to fulfill, forward, redirect, or reject the requests. Exactly which service is carried out for a particular request is based on a number of factors which include: the proxy server's capabilities, what is requested, information contained in the request, where the request came from, the intended destination, and in some cases, who sent the request.
An advantage of a proxy server is that its cache can serve all users. If one or more Internet sites are frequently requested, these are likely to be in the proxy's cache, which will improve user response time. In fact, there are special servers called cache servers. A proxy can also do logging.
HTTP Server (powered by Apache) has proxy server capabilities built in. Activating these services is simply a matter of configuration. This topic explains three common proxy concepts: forward proxy, reverse proxy, and proxy chaining.
Forward proxy :
A forward proxy is the most common form of a proxy server and is generally used to pass requests from an isolated, private network to the Internet through a firewall. Using a forward proxy, requests from an isolated network, or intranet, can be rejected or allowed to pass through a firewall. Requests may also be fulfilled by serving from cache rather than passing through the Internet. This allows a level of network security and lessens network traffic.
A forward proxy server will first check to make sure a request is valid. If a request is not valid, or not allowed (blocked by the proxy), it will reject the request resulting in the client receiving an error or a redirect. If a request is valid, a forward proxy may check if the requested information is cached. If it is, the forward proxy serves the cached information. If it is not, the request is sent through a firewall to an actual content server which serves the information to the forward proxy. The proxy, in turn, relays this information to the client and may also cache it, for future requests.
Reverse proxy
A reverse proxy is another common form of a proxy server and is generally used to pass requests from the Internet, through a firewall to isolated, private networks. It is used to prevent Internet clients from having direct, unmonitored access to sensitive data residing on content servers on an isolated network, or intranet. If caching is enabled, a reverse proxy can also lessen network traffic by serving cached information rather than passing all requests to actual content servers. Reverse proxy servers may also balance workload by spreading requests across a number of content servers. One advantage of using a reverse proxy is that Internet clients do not know their requests are being sent to and handled by a reverse proxy server. This allows a reverse proxy to redirect or reject requests without making Internet clients aware of the actual content server (or servers) on a protected network.
A reverse proxy server will first check to make sure a request is valid. If a request is not valid, or not allowed (blocked by the proxy), it will not continue to process the request resulting in the client receiving an error or a redirect. If a request is valid, a reverse proxy may check if the requested information is cached. If it is, the reverse proxy serves the cached information. If it is not, the reverse proxy will request the information from the content server and serve it to the requesting client. It also caches the information for future requests.
Proxy chaining
A proxy chain uses two or more proxy servers to assist in server and protocol performance and network security. Proxy chaining is not a type of proxy, but a use of reverse and forward proxy servers across multiple networks. In addition to the benefits to security and performance, proxy chaining allows requests from different protocols to be fulfilled in cases where, without chaining, such requests would not be possible or permitted. For example, a request using HTTP is sent to a server that can only handle FTP requests. In order for the request to be processed, it must pass through a server that can handle both protocols. This can be accomplished by making use of proxy chaining which allows the request to be passed from a server that is not able to fulfill such a request (perhaps due to security or networking issues, or its own limited capabilities) to a server that can fulfill such a request.
The first proxy server in a chain will check to make sure a request is valid. If a request is not valid, or not allowed (blocked by the proxy), it will reject the request resulting in the client receiving an error or a redirect. If a request is valid, the proxy may check if the requested information is cached and simply serve it from there. If the requested information is not in cache, the proxy will pass the request on to the next proxy server in the chain. This server also has the ability to fulfill, forward, redirect, or reject the request. If it acts to forward the request then it too passes the request on to yet another proxy server. This process is repeated until the request reaches the last proxy server in the chain. The last server in the chain is required to handle the request by contacting the content server, using whatever protocol is required, to obtain the information. The information is then relayed back through the chain until it reaches the requesting client.
The Squid web caching proxy server
Users configure their web browsers to use the Squid proxy server instead of going to the web directly. The Squid server then checks its web cache for the web information requested by the user. It will return any matching information that finds in its cache, and if not, it will go to the web to find it on behalf of the user. Once it finds the information, it will populate its cache with it and also forward it to the user's web browser.
As you can see, this reduces the amount of data accessed from the web. Another advantage is that you can configure your firewall to only accept HTTP web traffic from the Squid server and no one else. Squid can then be configured to request usernames and passwords for each user that users its services. This provides simple access control to the Internet
Subscribe to:
Comments (Atom)
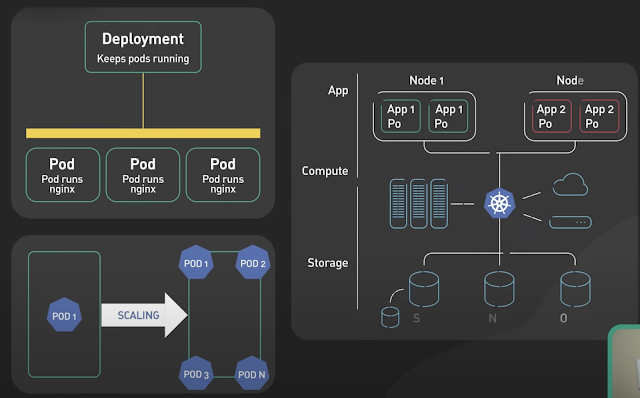
Basics of Kubernetes
Kubernetes, often abbreviated as K8s , is an open-source platform designed to automate the deployment, scaling, and management of container...
-
The Unix top command is designed to help users determine which processes are running and which applications are using more memory or process...
-
 IOPS (input/output operations per second) is the standard unit of measurement for the maximum number of reads and writes to non-contiguous ...
IOPS (input/output operations per second) is the standard unit of measurement for the maximum number of reads and writes to non-contiguous ... -
 MySQL's InnoDB storage engine data refresh every situation. This post from InnoDB down, look at the data from the memory to the InnoDB ...
MySQL's InnoDB storage engine data refresh every situation. This post from InnoDB down, look at the data from the memory to the InnoDB ...